

If you want a really good method of identifying a legacy C++ library/framework, see if it provides a vector class. For C this would be a set of vector functions. Arrays in C and C++ are hard coded at compile time. This dates back to the beginning of the languages. During the early 1980s VAX BASIC was the only widely used programming language supporting dynamic arrays.
1 SUB BAS_SQLM_ZILL_BROWSE_SUB
OPTION TYPE=EXPLICIT
. . .
!
! Record we will use to dimension the scrolling array.
!
RECORD SCRN_RECORD
STRING F_MARK = 1%
STRING DRAW_DT = 10%
STRING NUMBERS = 30%
STRING MEGA_NO = 2%
END RECORD
. . .
100 L_ERR% = 0%
L_REC_COUNT% = 0%
CALL COUNT_DRAW( SQLCODE%, L_REC_COUNT%)
CALL COMMIT_MEGA( SQLCODE%)
DIM DRAWING_RECORD D_REC( L_REC_COUNT%)
. . .You may not be familiar with BASIC but the last line starting with DIM is the line of interest. The full BASIC command is DIMENSION and it dynamically creates an array of any size (within the limits of memory/OS). You could even Re-dimension it provided you had enough memory. In the early days of relational databases when you could navigate a cursor in any direction you wanted, as long as it was forward, this was priceless. You could obtain the row count, size the array, then load the cursor into the array and dance around at will. If you want to know more about that obtain a copy of this book.
C
I lost count of the C libraries written over the years to deal with dynamic arrays. Keep in mind that under DOS you had a 640K memory wall and were lucky if you had even 512K for your program once the OS and device drivers got loaded. C provided the malloc() family for dynamic allocation, but you had to keep track of it. If it wasn’t for the fact strings were ASCII character arrays, hard coding maximum sizes at compile time wouldn’t have been that big of a problem. Way too many programmers hard coded stuff like this:
char resp[4];Then they didn’t force any limit to the input assuming users wouldn’t type more than 3 characters for a Yes/No response.
Segment:Offset
I have written about segment:offset before. This was a heinous artifact of x86 architecture. Each segment was 64KB in size. Many C compilers of the day only compared the offset when comparing pointers. If your allocation spanned two segments the ending offset was a lower number than the beginning.

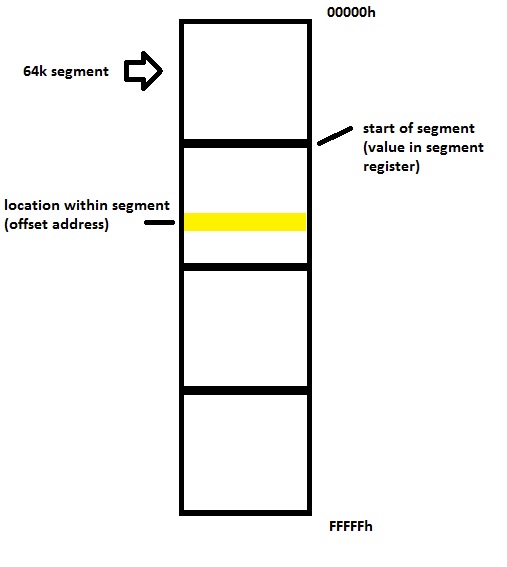
We will skip the whole “grow towards zero” and Big Endian vs. Little Endian arguments for now. All you have to know is that from an addressing point of view these segments were stacked nose to tail starting from the beginning of addressable RAM (whichever end that was) to the end. If you needed 100K for your array, it crossed a segment boundary. This loop would either fail to execute at all or run to the end of RAM getting an access violation.
char str[MAX_STRING_SIZE];
...
for (char *ptr = &str[0]; ptr < &str[MAX_STRING_SIZE]; ++ptr)
C++
Early C++ did not magically fix this. The first compiler was Cfront and it was really a translator that generated C source and ran the C compiler. I don’t even remember what the original C++ string classes were like. I just remember that every C++ GUI/framework library rolled their own. C-Scape was an early one on DOS. You can’t even find mention of it online anymore. Zinc I used and wrote books on. You can find OpenZinc but I don’t know if it is actually maintained. Every legacy library had its own String class and a Vector class for dynamic arrays. (At the time Vector sounded sexier.)
Each of these libraries tried to shield developers from the evils of x86 architecture. Many/most of them provided garbage collection. The caveat with every library claiming to add garbage collection is that all things had to be derived from “the one” base Object class they provided. Everything had to run under a “main eventloop” which had different names for different libraries. Even if they supported threading this basically made the library single threaded.
STL
The Standard Template Library (STL) was supposed to solve all problems, initially it was not even close. Templates were and still are a rather ugly thing. STL at least has thousands of developers beating on it and filing bug reports. That template you created to solve an in-house problem, not-so-much. Eventually STL gave us std::string and std::wstring.
typedef basic_string<char> string;
typedef basic_string<wchar_t> wstring;By and large, these were just well hidden arrays of C character types. For those who don’t know, the “w” is for wide characters. C had an internationalization problem. The rest of the world was putting up a stink about having to learn English and use ASCII for all printed and displayed characters. How dare they! wchar_t didn’t fix that problem.

Yes, the official documentation says theses are non-array type yada yada, but the data() and c_str() methods create arrays. A more accurate description would be these are possibly non-contiguous sets of some data type where chunks can be dynamically allocated and freed without user intervention. The char8_t, char16_t, and char32_t are for Unicode characters. You can see by the standards dates just how bass-ackwards this was implemented.
The wchar_t existed in the early 1990s (possibly late 1980s) as an implementation defined multi-byte (at least 2) character encoding. It allowed applications to support internationalization as long as they didn’t store or transmit that data to a different platform. See all the fun you young-ins missed!
Why so much time on strings?
Because that is what got us in trouble. The first versions of BASIC had both STRING variables and dynamic arrays. The concept was separated for beginning programmers. All strings were initially dynamic then many dialects introduced fixed length strings (like you see in the initial BASIC code snippet). Early BASIC limited strings to 255 bytes. The very first byte of the STRING data was an unsigned int containing the length. Later versions on non-x86 platforms had no real limit for dynamic and fixed length strings strictly enforced boundaries. Each of these types could be dimensioned into an array.
C was developed to be a portable Assembly language. Most Assembly languages had no concept of Text or String, they understood both signed and unsigned integers, some understood PACKED-DECIMAL, all other data types were just a collection of bytes. The programmer had to figure that out. Neither C nor UNIX were meant to escape into the wild from Bell Labs, but they did. Thus three decades of trying to un-screw the universe from treating STRING as an array of ASCII coded bytes ensued.
CoW
Copy on Write (CoW) was explicitly allowed in C++03 and existed in C++98 but banned from C++11 on. The initial basic_string supported CoW. Multi-core CPUs and Multi-Threading made it almost impossible to allow.
If you are using an application framework or C++ class library that utilizes CoW then you are using something looking up at Legacy hoping to one day be that new and modern. “Modern C++” is C++11. When you hear someone wanting “Modern C++” that’s what they are looking for. A massive chunk of C++11 code exists out there. Despite C++20 standard being out and newer standards being worked on C++17 is only now starting to be used. Ask any ten C++ developers and none of them will have heard of C++14.
In the world of “Modern C++” and beyond CoW is illegal. Only ancient packages looking up at Legacy still implement it. Yo don’t want to use them for anything new.
Why did CoW exist?
This were slow. The original IBM PC and clones ran at 4.77mhz. DOS had a hard 640K limit that you could not get all of. Passing strings around was expensive if you had to dynamically allocate a fresh copy every time. There was a severe risk you would run out of RAM. If you just had to pass an address and adjust a reference counter, only making a fresh copy if something wanted to modify the string, you ran way faster.
We only had one core, we didn’t have to worry about core 16 reaching across all of the other cores to monkey with the string we were using. We did still have to worry about the fool who forgot to initialize a pointer randomly overwriting it though.
Background Summary
Initially tying strings to arrays set vector development back at least a decade if not more. The academics wanted us to use the term Array for fixed length compiler allocated arrays and Vector for dynamically allocated arrays which thoroughly put off thousands of developers who learned BASIC first.
std::string s("str");
const char* p = s.data();
{
std::string s2(s);
(void) s[0];
}
std::cout << *p << '\n'; // p is danglingPrior to C++11 GCC’s old reference-counted std::string implementation, the above code has undefined behavior, because p is invalidated by s[0] becoming a dangling pointer. It would work “some” of the time with sloppy implementations that did not immediately reclaim the freed storage. In a multi-threaded world it would cause random crashes because the storage got re-used for something else. What happens is that when s2 is constructed it shares the data with s, but obtaining a non-const reference via s[0] requires the data to be unshared, so s does a “copy on write” because the reference s[0] could potentially be used to write into s, then s2 goes out of scope, destroying the array pointed to by p. C++11 made this illegal for good reason.
The Example
#include <iostream>
#include <iomanip>
#include <vector>
#include "config.h"
int main(int argc, char **argv) {
std::cout << "VectorContainerExample" << std::endl;
std::cout << "Version " << VectorContainerExample_VERSION_MAJOR << "." << VectorContainerExample_VERSION_MINOR << std::endl;
std::vector<double> x; // stores data to be sorted
while (true)
{
double input {};
std::cout << "Enter a non-zero value, or 0 to end: ";
std::cin >> input;
if (input == 0)
{
break;
}
x.push_back(input);
}
if (x.empty())
{
std::cout << "Nothing to sort . . ." << std::endl;
return 0;
}
std::cout << "Starting sort." << std::endl;
// This is a bubble sort. Since we are sorting in Ascending order
// after the first pass the largest value is at the end. We have no
// need to look at it again.
//
size_t last = x.size();
// Crashing out of an infinite loop is bad style.
//
bool done = false;
while (!done)
{
bool swapped{false}; // set to true when we swap
for (size_t i{}; i < last - 1; ++i)
{
if (x[i] > x[i+1])
{
std::swap( x[i], x[i+1]);
swapped = true;
}
}
--last;
if (!swapped || (last == 0))
{
done = true;
}
}
std::cout << "Your data in ascending sequence:\n"
<< std::fixed << std::setprecision(2);
const size_t perline {10}; // number output per line
size_t n {}; // number on current line
for ( double dbl : x)
{
std::cout << std::setw(8) << dbl;
if (++n == perline)
{
std::cout << std::endl; // start new line
n = 0; // reset count
}
}
std::cout << std::endl;
return 0;
}
I created this in Eclipse as a CMake project based on their Hello World! template. You can find many versions of this example online and in textbooks. We will show two different versions.
Line 11 is where we declare a vector of doubles named x. Lines 13 through 23 are where we punish the user making them enter all of the numbers by hand. 25-29 is a sanity check. You learn how to properly do a bubble sort in lines 33 through 59. Lines 61 through 77 is where we dump the output.
VectorContainerExample Version 0.1 Enter a non-zero value, or 0 to end: 1.3 Enter a non-zero value, or 0 to end: 0.5 Enter a non-zero value, or 0 to end: 667 Enter a non-zero value, or 0 to end: 123.01 Enter a non-zero value, or 0 to end: -1.2 Enter a non-zero value, or 0 to end: 25.1 Enter a non-zero value, or 0 to end: 999 Enter a non-zero value, or 0 to end: 0 Starting sort. Your data in ascending sequence: -1.20 0.50 1.30 25.10 123.01 667.00 999.00
Most of the examples will create temporary variables when swapping but if you are going to use std::vector, you might as well use std::swap(). In fact, lets clean this up further.
Less Code More STL
#include <iostream>
#include <iomanip>
#include <vector>
#include <algorithm>
#include "config.h"
int main(int argc, char **argv) {
std::cout << "VectorContainerExample" << std::endl;
std::cout << "Version " << VectorContainerExample_VERSION_MAJOR << "." << VectorContainerExample_VERSION_MINOR << std::endl;
std::vector<double> x; // stores data to be sorted
while (true)
{
double input {};
std::cout << "Enter a non-zero value, or 0 to end: ";
std::cin >> input;
if (input == 0)
{
break;
}
x.push_back(input);
}
if (x.empty())
{
std::cout << "Nothing to sort . . ." << std::endl;
return 0;
}
std::cout << "Starting sort." << std::endl;
std::sort( x.begin(), x.end());
std::cout << "Your data in ascending sequence:\n"
<< std::fixed << std::setprecision(2);
const size_t perline {10}; // number output per line
size_t n {}; // number on current line
for ( double dbl : x)
{
std::cout << std::setw(8) << dbl;
if (++n == perline)
{
std::cout << std::endl; // start new line
n = 0; // reset count
}
}
std::cout << std::endl;
return 0;
}
At line 4 we include algorithm to get std::sort. The entire bubble sort gets replaced by line 34. We just want an ascending sort and don’t care what algorithm they wish to use.
VectorContainerExample Version 0.1 Enter a non-zero value, or 0 to end: -333 Enter a non-zero value, or 0 to end: 1.11111 Enter a non-zero value, or 0 to end: 1.11112 Enter a non-zero value, or 0 to end: 55 Enter a non-zero value, or 0 to end: 21.4 Enter a non-zero value, or 0 to end: 1.01 Enter a non-zero value, or 0 to end: 699.95 Enter a non-zero value, or 0 to end: 0.2345 Enter a non-zero value, or 0 to end: 0 Starting sort. Your data in ascending sequence: -333.00 0.23 1.01 1.11 1.11 21.40 55.00 699.95
I deliberately entered 1.11111 and 1.11112 to infuriate you. Because precision was set to two for output we don’t know std::sort got it right. Since floating point is always an approximation you can end up having issues sorting floating point.
Summary
C/C++ have spent a lot of years trying to catch up to VAX BASIC. The languages to this day still don’t have record I/O or native indexed file support. You have to use third party libraries for that. What has been rolled into STL is so huge most people can’t begin to know it. At least now you know about std::vector and how to use it.